The relational data model is a conceptual data model in which data is represented by a collection of relations (or tables).
A relation on sets ![]() ,
, ![]() , ...
, ... ![]() is a subset of the
cartesian product of
is a subset of the
cartesian product of ![]() ,
, ![]() , ...,
, ..., ![]() .
.
The cartesian product of ![]() ,
, ![]() , ...,
, ..., ![]() , written
, written
![]() , is the set of all possible
tuples:
, is the set of all possible
tuples:
![]()
Example - the fly relation:
| pattern | size | color | fly-stock-num |
|---|---|---|---|
| woolly bugger | 10 | olive | 5 |
| gold-ribbed hare's ear | 14 | natural | 2 |
| woolly bugger | 2 | black | 4 |
| Dahlberg Diver | 2 | natural | 1 |
A tuple variable t is a variable that ranges over a relation (its domain is a relation). The value held by a tuple variable at any time is a tuple.
Notation: t ![]() r denotes that t is a tuple in r (the domain of t is r).
t[attribute-name] denotes the value of the named attribute in tuple t.
r denotes that t is a tuple in r (the domain of t is r).
t[attribute-name] denotes the value of the named attribute in tuple t.
Example: if t ![]() fly, then t has 3 possible values and the possible
values of t[size] are 2, 10, 14
fly, then t has 3 possible values and the possible
values of t[size] are 2, 10, 14
The column number may be used in place of the attribute name. Example:
t[2] ![]() t[size]
t[size]
Review:
In the relational model, a relation scheme is a list of the attributes of a relation, possibly including the domains of the attributes.
Example: the relation scheme for fly is (pattern, size, color, fly-stock-num) or (pattern: string[30], size: integer, color :{black, olive, natural}, fly-stock-num: integer)
Notation:
Example: the scheme of relation fly is Fly-scheme
The scheme of a relational database consists of the schemes of all the relations in the database.
Schemes for the flyshop database:
| scheme name | attributes |
|---|---|
| Fly-scheme | (pattern, size, color, fly-stock-num) |
| Customer-scheme | (name, address, cust-num) |
| Flyrod-scheme | (manufacturer, length, line-weight, flyrod-stock-num) |
| Purchased-scheme | (cust-num, flyrod-stock-num, date) |
| Requested-By-scheme | (fly-stock-num, cust-num) |
| Fave-Combo-scheme | (cust-num, flyrod-stock-num, fly-stock-num) |
Notes:
The use of the same attribute names in different relations is a way of relating tuples of different relations.
Example query: find the addresses of all customers who have purchased a Sage 2-weight.
Solution:
Question: should we use one relation with scheme (name, address, cust-num, manufacturer, length, line-weight, flyrod-stock-num, date, pattern, size, color, fly-stock-num) rather than the current 6 relations?
Problems with using one big relation:
Problems caused by duplication:
Note that our database scheme avoids many of these problems:
The concepts of superkey, candidate key and primary key from the E-R model apply directly to the relational model.
A superkey is a subset of the attributes of a relation scheme that uniquely distinguish any tuple in a relation on that scheme.
Example - for relations on Flyrod-scheme, the superkeys include:
A candidate key is a superkey that has no superkeys as proper subsets.
Example - for relations on Flyrod-scheme, the candidate keys are:
The primary key is the (one) candidate key designated as the main way to distinguish tuples in the relation
Example: for relations on Flyrod-scheme, we'll designate {flyrod-stock-num} as the primary key.
Notation: we extend [ ] (indexing into tuple variables) to work with sets of attributes. The result will be a tuple of the values of attributes in the set.
Example: if t ![]() customer and t = (Tim Wahls, E258, 1), then
t[{name, address}] = (Tim Wahls, E258)
customer and t = (Tim Wahls, E258, 1), then
t[{name, address}] = (Tim Wahls, E258)
Formally, let R be a relation scheme and r a relation on that scheme, i.e.
r(R), and K ![]() R such that K =
R such that K = ![]() . If t
is a tuple variable and t
. If t
is a tuple variable and t ![]() r, then:
r, then:
![]()
Fundamental property of a superkey: if R is a relation scheme, then
K ![]() R is a superkey for R if and only if for every relation r(R),
R is a superkey for R if and only if for every relation r(R),
if ![]() r and
r and ![]() r and
r and ![]() , then
, then ![]() [K]
[K] ![]() [K]
[K]
equivalently, if ![]() [K] =
[K] = ![]() [K], then
[K], then ![]() =
= ![]()
A superkey is a property of a relation scheme, not a relation. A superkey must be a superkey for every relation on the scheme.
Formally, if r is a relation with the same attributes as R and K ![]() R
is a superkey for R, but
R
is a superkey for R, but ![]() r and
r and ![]() r and
r and ![]() [K] =
[K] = ![]() [K]
and
[K]
and ![]() , then it is not the case that r(R), i.e. r is not a relation
on scheme R.
, then it is not the case that r(R), i.e. r is not a relation
on scheme R.
Review: a query language is a language used to retrieve information from a database. It is usually part of a data manipulation language (DML).
"Pure" query languages for relational databases:
These languages are called pure because they are very formal, and because they include none of the non-query functionality of a DML (delete, insert, modify).
Relational algebra is a procedural query language - users write tiny algorithms in relational algebra for finding the information to be retrieved. Relational algebra is the basis for the commercial language SQL.
Tuple relational calculus and domain relational calculus are nonprocedural query languages - users describe the information they need in variants of first order predicate logic, and the system is responsible for finding that information. Tuple relational calculus is the basis for the commercial language Quel, and domain relational calculus is the basis for the commercial language QBE.
Relational algebra is a set of operations that take relations as arguments. All relational algebra operations except assignment return relations as their result.
There are two kinds of relational operations:
Fundamental operations (unary):
Fundamental operations (binary):
Nonfundamental operations:
Examples involving these operations use the following relations:
| manufacturer | length | line-weight | flyrod-stock-num |
|---|---|---|---|
| Sage | 7.0 | 2 | 3 |
| G. Loomis | 8.5 | 6 | 1 |
| Orvis | 9.5 | 9 | 2 |
| pattern | size | color | fly-stock-num |
|---|---|---|---|
| woolly bugger | 10 | olive | 5 |
| gold-ribbed hare's ear | 14 | natural | 2 |
| woolly bugger | 2 | black | 4 |
| Dahlberg Diver | 2 | natural | 1 |
| name | address | cust-num |
|---|---|---|
| Tim Wahls | E258 | 1 |
| Linda Null | E258 | 3 |
| Elvis Presley | Graceland | 2 |
| cust-num | flyrod-stock-num | date |
|---|---|---|
| 1 | 3 | 9/4/1994 |
| 3 | 3 | 9/3/1994 |
| 2 | 2 | 8/8/1992 |
| 3 | 2 | 9/2/1994 |
| 3 | 1 | 9/1/1994 |
| cust-num | fly-stock-num |
|---|---|
| 1 | 2 |
| 3 | 5 |
| 2 | 4 |
| 2 | 1 |
The select operation chooses (or selects) tuples from a relation that satisfy a given condition (called a predicate). The result is a relation that is a subset of the argument relation.
Example: selecting all flyrods over 8.0 feet long from flyrod produces:
| manufacturer | length | line-weight | flyrod-stock-num |
|---|---|---|---|
| G. Loomis | 8.5 | 6 | 1 |
| Orvis | 9.5 | 9 | 2 |
The result of a select operation can be the entire argument relation or the empty relation.
Notation: The Greek letter sigma ( ![]() ) is the usual symbol for select.
The selection predicate is written as a subscript of
) is the usual symbol for select.
The selection predicate is written as a subscript of ![]() , and the argument
relation is written in parenthesis.
, and the argument
relation is written in parenthesis.
Example - in this notation, the previous query is:
![]()
The selection predicate can refer to attribute names and constants of the
attributes' domains. The following comparisons can be used: =, ![]() ,
<,
,
<, ![]() , >,
, >, ![]() . Predicates can be built using boolean operators
. Predicates can be built using boolean operators
![]() (logical and) and
(logical and) and ![]() (logical or).
(logical or).
Example:
![]()
produces the relation:
| manufacturer | length | line-weight | flyrod-stock-num |
|---|---|---|---|
| Orvis | 9.5 | 9 | 2 |
The selection predicate may compare two attributes:
![]()
produces the empty relation:
| manufacturer | length | line-weight | flyrod-stock-num |
|---|
The project operation is used to remove attributes (and the associated columns) from a relation. For example, if we only wanted to know what lengths of flyrods are we stock from particular manufacturers, we would project the flyrod relation on the manufacturer and length attributes, producing:
| manufacturer | length |
|---|---|
| Sage | 7.0 |
| G. Loomis | 8.5 |
| Orvis | 9.5 |
If multiple tuples have the same values for the attributes projected on, the result of a projection will have fewer tuples than the argument relation.
Example: if there were a 7 foot Sage 5-weight as well as the 7 foot Sage 2-weight, the result of a projection on manufacturer and length would be the same as above.
Notation: The Greek letter pi ( ![]() ) is the usual symbol for project.
The list of attributes to project on is written as a subscript of
) is the usual symbol for project.
The list of attributes to project on is written as a subscript of ![]() , and
the argument relation is written in parenthesis.
, and
the argument relation is written in parenthesis.
Example - in this notation, the previous query is:
![]()
To see just the manufacturers of flyrods carried by the shop that are over 8.0 feet long, compose a select and a project operation. That is, the result of a selection becomes the argument of a projection:
![]()
producing:
| manufacturer |
|---|
| G. Loomis |
| Orvis |
The cartesian product combines information from several relations in answering
a query. The cartesian product of relations ![]() and
and ![]() is written
is written
![]() and pronounced
and pronounced ![]() cross
cross ![]() .
.
Cartesian product for relational algebra is like cartesian product for sets, except that:
Attributes of the result of a cartesian product are named by attaching the name of the argument relation to the name of it's attributes in the result.
Example: the relation scheme of customer ![]() purchased is:
purchased is:
(customer.name, customer.address, customer.cust-num, purchased.cust-num, purchased.flyrod-stock-num, purchased.date)
If an attribute appears in only one relation scheme, we drop the relation name prefix, yielding:
(name, address, customer.cust-num, purchased.cust-num, flyrod-stock-num, date)
Formally, for relations ![]() and
and ![]() , the scheme of
, the scheme of
![]() is produced by concatenating
is produced by concatenating ![]() and
and ![]() , and then
prefixing any duplicate attribute names with the name of the relation that
the attribute came from.
, and then
prefixing any duplicate attribute names with the name of the relation that
the attribute came from.
Tuples of ![]() are produced by every possible concatenation
of a tuple in
are produced by every possible concatenation
of a tuple in ![]() with a tuple in
with a tuple in ![]() .
.
Example - customer ![]() purchased is:
purchased is:
| name | address | customer.cust-num | purchased.cust-num | flyrod-stock-num | date |
|---|---|---|---|---|---|
| Tim Wahls | E258 | 1 | 1 | 3 | 9/4/1994 |
| Tim Wahls | E258 | 1 | 3 | 3 | 9/3/1994 |
| Tim Wahls | E258 | 1 | 2 | 2 | 8/8/1992 |
| Tim Wahls | E258 | 1 | 3 | 2 | 9/2/1994 |
| Tim Wahls | E258 | 1 | 3 | 1 | 9/1/1994 |
| Linda Null | E258 | 3 | 1 | 3 | 9/4/1994 |
| Linda Null | E258 | 3 | 3 | 3 | 9/3/1994 |
| Linda Null | E258 | 3 | 2 | 2 | 8/8/1992 |
| Linda Null | E258 | 3 | 3 | 2 | 9/2/1994 |
| Linda Null | E258 | 3 | 3 | 1 | 9/1/1994 |
| Elvis Presley | Graceland | 2 | 1 | 3 | 9/4/1994 |
| Elvis Presley | Graceland | 2 | 3 | 3 | 9/3/1994 |
| Elvis Presley | Graceland | 2 | 2 | 2 | 8/8/1992 |
| Elvis Presley | Graceland | 2 | 3 | 2 | 9/2/1994 |
| Elvis Presley | Graceland | 2 | 3 | 1 | 9/1/1994 |
The size of ![]() is
is ![]() , where
, where ![]() is the
size of
is the
size of ![]() .
.
Discussion: which tuples in the result of customer ![]() purchased
represent meaningful relationships?
purchased
represent meaningful relationships?
Answer: Only those where the cust-num attributes contain the same value. Other tuples match customers with flyrods that they didn't buy.
We restrict the result to only the meaningful tuples with an appropriate selection:
![]()
which produces:
| name | address | customer.cust-num | purchased.cust-num | flyrod-stock-num | date |
|---|---|---|---|---|---|
| Tim Wahls | E258 | 1 | 1 | 3 | 9/4/1994 |
| Linda Null | E258 | 3 | 3 | 3 | 9/3/1994 |
| Linda Null | E258 | 3 | 3 | 2 | 9/2/1994 |
| Linda Null | E258 | 3 | 3 | 1 | 9/1/1994 |
| Elvis Presley | Graceland | 2 | 2 | 2 | 8/8/1992 |
Finally, use a project to get rid of one of the duplicate columns:
![]()
producing:
| name | address | customer.cust-num | flyrod-stock-num | date |
|---|---|---|---|---|
| Tim Wahls | E258 | 1 | 3 | 9/4/1994 |
| Linda Null | E258 | 3 | 3 | 9/3/1994 |
| Linda Null | E258 | 3 | 2 | 9/2/1994 |
| Linda Null | E258 | 3 | 1 | 9/1/1994 |
| Elvis Presley | Graceland | 2 | 2 | 8/8/1992 |
Example: find all dates on which Linda Null purchased a flyrod.
![]()
which produces:
| date |
|---|
| 9/3/1994 |
| 9/2/1994 |
| 9/1/1994 |
A composition of selections is equivalent to a single selection which has a selection predicate built by conjoining (``anding") all of the original selection predicates.
Example:
![]()
is equivalent to the previous query.
Multiple applications of cartesian product can be used to answer queries involving more than two relations.
Example - List all manufacturers of flyrods purchased by Elvis Presley:
![]()
![]()
which produces:
| manufacturer |
|---|
| Orvis |
Discussion - can we write the query: ``Find all customers who have the same address as Tim Wahls" in the subset of relational algebra discussed so far?
We need to reference the customer relation twice in the same query:
![]()
Discussion: what is wrong with this query?
The outermost selection predicate is ambiguous, because it is being applied to a relation with two customer.address attributes.
Solution: we need an operation to change the name of a relation. If we could change the name of one occurrence of customer, the ambiguity would be resolved.
Notation: the rename operation is symbolized by the Greek letter rho
( ![]() ), and an application of this operation is written:
), and an application of this operation is written: ![]() .
The result is a relation with the same attributes and tuples as r, but with
name x.
.
The result is a relation with the same attributes and tuples as r, but with
name x.
Example - ``Find the names of all customers who have the same address as Tim Wahls":
![]()
producing:
| name |
|---|
| Tim Wahls |
| Linda Null |
The flyshop database can be expanded with an employee relation that records information about employees of the flyshop.
| name | address | social-security-num | salary |
|---|---|---|---|
| Elvis Presley | Graceland | 121212121 | 25000 |
| Debbie Jackson | Neverland | 343434343 | 32000 |
| Tito Jackson | P.O. Box 37 | 232323232 | 1000 |
Employee-scheme = (name, address, social-security-num, salary)
Suppose the flyshop wants to send a newsletter to all employees and customers. We need the names and addresses of both customers and employees in one relation.
Since relations are sets of tuples, unioning the relations seems sensible. However, the relations are on different schemes (and so have different types).
Solution: use appropriate projections.
![]()
which produces:
| name | address |
|---|---|
| Elvis Presley | Graceland |
| Debbie Jackson | Neverland |
| Linda Null | E258 |
| Tito Jackson | P.O. Box 37 |
| Tim Wahls | E258 |
Note that the standard set union symbol is used.
Discussion - should Elvis appear twice?
Two relations ![]() and
and ![]() can be unioned if they are compatible.
Compatibility means:
can be unioned if they are compatible.
Compatibility means:
The order of attributes of a relation can be changed using projection because
the order of attributes in the result relation is the same as the order given
in the subscript of ![]() .
.
Example - to reverse the order of attributes in the newsletter relation:
![]()
The attributes of the result of applying the union operation can be named in any convenient fashion.
To find all customers who are not also employees, use the set difference operation.
Review: the difference of two sets S1 and S2, written S1 - S2, is the set of all elements of S1 that are not also elements of S2.
As with union, the arguments of set difference must be compatible relations, and the attribute names of the result are arbitrary.
Example:
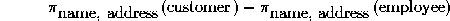
producing:
| name | address |
|---|---|
| Linda Null | E258 |
| Tim Wahls | E258 |
An inductive definition is recursive - it defines something in terms of itself.
Example - an inductive definition of arithmetic terms:
basis: a real number is an arithmetic term
inductive definition: if ![]() and
and ![]() are arithmetic terms, then all of
the following are arithmetic terms:
are arithmetic terms, then all of
the following are arithmetic terms:
![]()
![]()
![]()
![]()
![]()
By applying this definition, we can generate an infinite number of arithmetic terms. For example, 3, 4, and 5.2 are terms (by the basis) and so are:
3 + 4
(3 + 4)
(3 + 4)/5.2
An inductive definition of relational algebra expressions:
basis: the names of relations in the database and constant relations (entire tables appearing in queries) are relational algebra expressions
inductive definition: if ![]() and
and ![]() are relational algebra expressions,
then all of the following are relational algebra expressions:
are relational algebra expressions,
then all of the following are relational algebra expressions:
![]()
![]()
![]()
![]() where P is a predicate on the attributes of
where P is a predicate on the attributes of ![]()
![]() where S is a list of attribute names of
where S is a list of attribute names of ![]()
![]() where x is a string containing the new name for
where x is a string containing the new name for ![]()
![]()
The following operations can be defined in terms of the fundamental operations, but often make writing queries easier.
Example: to find the name and address of everyone who is both an employee and a customer of the flyshop:
![]()
It is easier to write:
![]()
![]()
The result of customer ![]() purchased puts customers together with
purchases they didn't make. Both a select and a project were needed to make
the result useful.
purchased puts customers together with
purchases they didn't make. Both a select and a project were needed to make
the result useful.
The natural join operation combines a cartesian product operation with
these selects and projects. The natural join of customer and purchased,
written customer ![]() purchased, is computed by:
purchased, is computed by:
Producing:
| name | address | cust-num | flyrod-stock-num | date |
|---|---|---|---|---|
| Tim Wahls | E258 | 1 | 3 | 9/4/1994 |
| Linda Null | E258 | 3 | 3 | 9/3/1994 |
| Linda Null | E258 | 3 | 2 | 9/2/1994 |
| Linda Null | E258 | 3 | 1 | 9/1/1994 |
| Elvis Presley | Graceland | 2 | 2 | 8/8/1992 |
In general, to compute r ![]() s:
s:
Natural join is formally defined as follows: Let R and S be relation
schemes, and r(R) and s(S). Think of R and S as sets, rather than lists of
attribute names. R ![]() S is the set of attribute names that appear in
both schemes, and R
S is the set of attribute names that appear in
both schemes, and R ![]() S is the scheme of r
S is the scheme of r ![]() s. The tuples in
the result are:
s. The tuples in
the result are:
r ![]()
![]()
where R ![]() S =
S = ![]()
The selection refers to ![]() ,
, ![]() and so on, but the projection
refers to
and so on, but the projection
refers to ![]() ,
, ![]() , ... Technically, this isn't a sensible relational
algebra expression, but the idea is that
, ... Technically, this isn't a sensible relational
algebra expression, but the idea is that ![]() could be either
could be either ![]() or
or ![]() , because the columns are identical after the selection.
, because the columns are identical after the selection.
If R ![]() S =
S = ![]() (i.e. the relation schemes have no attributes
in common), then for r(R) and s(S):
(i.e. the relation schemes have no attributes
in common), then for r(R) and s(S):
r ![]()
![]()
Example - find all information about customers and their flyrod purchases:
![]()
![]()
![]()
![]()
![]()
Because ![]() is associative, we don't need parentheses. I.e:
is associative, we don't need parentheses. I.e:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The result of this query is:
| name | address | cust-num | flyrod-stock-num | date | manufacturer | length | line-weight |
|---|---|---|---|---|---|---|---|
| Tim Wahls | E258 | 1 | 3 | 9/4/1994 | Sage | 7.0 | 2 |
| Linda Null | E258 | 3 | 3 | 9/3/1994 | Sage | 7.0 | 2 |
| Linda Null | E258 | 3 | 2 | 9/2/1994 | Orvis | 9.5 | 9 |
| Linda Null | E258 | 3 | 1 | 9/1/1994 | G. Loomis | 8.5 | 6 |
| Elvis Presley | Graceland | 2 | 2 | 8/8/1992 | Orvis | 9.5 | 9 |
Example - find the names of all customers who have requested that the flyshop carry some size or color of woolly bugger:
![]()
![]()
![]()
![]()
![]()
producing:
| name |
|---|
| Linda Null |
| Elvis Presley |
Note that the scheme of ![]()
![]()
![]()
![]()
![]() is (name, address, cust-num,
fly-stock-num, pattern, size, color).
is (name, address, cust-num,
fly-stock-num, pattern, size, color).
The query:
![]()
![]()
![]()
![]()
![]()
is equivalent and more efficient to execute, because the only tuples from fly participating in the natural join are those whose pattern attribute is ``woolly bugger'', and so the relation resulting from the natural joins is smaller.
Suppose we wanted to find the cust-num of all customers who have purchased at least one of every kind of flyrod that the flyshop stocks.
One approach:
![]()
We'll call the result flyrod-nums.
| flyrod-stock-num |
|---|
| 1 |
| 2 |
| 3 |
![]()
We'll call the result has-purchased.
| cust-num | flyrod-stock-num |
|---|---|
| 1 | 3 |
| 3 | 3 |
| 3 | 2 |
| 3 | 1 |
| 2 | 2 |
Thus, this query would be written:
![]()
producing:
| cust-num |
|---|
| 3 |
Formally, the result of ![]() for r(R) and s(S) is a relation
on scheme R - S, where we require that S
for r(R) and s(S) is a relation
on scheme R - S, where we require that S ![]() R.
R.
A tuple t is in ![]() if (and only if) the following condition is
satisfied: For every tuple
if (and only if) the following condition is
satisfied: For every tuple ![]() in s there is a tuple
in s there is a tuple ![]() in r
such that:
in r
such that:
![]()
and ![]()
i.e. there is a group of tuples in r that all have the same values for
attributes in R - S, and have all values (subtuples) that occur in s for
attributes in S. Every tuple in this group has the same values for attributes
in R - S, and so the group contributes one tuple to the result of
![]() , because all tuples in the group are the same when restricted
to attributes in R - S.
, because all tuples in the group are the same when restricted
to attributes in R - S.
The division operator can be expressed in terms of fundamental operations, but this definition doesn't help understand what division means.
For complicated relational algebra expressions, it is convenient to use temporary relations to hold the results of some subexpressions.
Notation: assignment is written ![]()
Example - to compute customer ![]() purchased:
purchased:
temp ![]() customer
customer ![]() purchased
purchased
temp ![]()
![]()
temp ![]()
![]()
Now temp contains customer ![]() purchased.
purchased.
Because non-fundamental operations don't permit any queries to be expressed that can't be expressed using only fundamental operations, they don't add any expressive power to relational algebra. However, they do add to the expressiveness of relational algebra because they make writing queries easier.