

Comp 419
Database Design
Final Exam Study Question Answers
Note: these study questions and answers pertain only to material covered since the midterm. The final is comprehensive! See the midterm and study questions for the midterm for more study questions.
Customer-scheme = (name, address, cust-num)
Flyrod-scheme = (manufacture, length, line-weight, flyrod-stock-num)
Purchased-scheme = (cust-num, flyrod-stock-num, date)
One of the referential integrity constraints associated with this
flyshop database is:
![]()
purchased, what test
needs to be performed to insure that this referential integrity constraint
is maintained?customer, what test
needs to be performed to insure that this referential integrity constraint
is maintained?Part-scheme = (part-num, description, groovyness, quantity) Supplier-scheme = (supplier-name, address, phone-number) Supplies-scheme = (part-num, supplier-name, address, cost)The primary key for relations on
Part-scheme is part-num, and
the primary key for relations on Supplier-scheme is
{supplier-name, address}.
supplier and supplies relations? ![]()
part and supplies relations? Why or why not?part on the left of the supplies
on the right, because part-num is not the primary key for
supplies.
There is no referential integrity constraint that references
part on the right of the ![]() and
and supplies
on the left (even though part-num is the primary key
for part), because we only store parts that are in stock,
and we may very well keep track of suppliers for parts that aren't
in stock. Hence, there is no referential integrity constraint
between these two relations.
addresses do not share the same phone-number.phone-number addresssupplies as a
relationship set from supplier to part (E-R model), what is
the mapping cardinality of this relationship set?Supplies-scheme must satisfy.supplier-name, address part-num Allparts-scheme = (part-num, description, groovyness, quantity,
supplier-name, address, phone-number, cost)
and set of functional dependencies on that scheme:
F =Is the decomposition of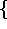
part-num
{description, groovyness, quantity},{supplier-name, address}phone-number
Allparts-scheme into Part-scheme,
Supplier-scheme, and Supplies-scheme a lossless-join
decomposition? Why or why not?Sup-scheme = (part-num, supplier-name, address, phone-number, cost)
The intersection of Part-scheme and Sup-scheme is
part-num, and part-num ![]()
Part-scheme.
(Easy proof omitted - make sure you include it in a similar situation
on the exam.) Hence, decomposing Allparts-scheme into
Sup-scheme and Part-scheme is a lossless join
decomposition.
Now decompose Sup-scheme into Supplier-scheme and
Supplies-scheme. The intersection of these schemes
is {supplier-name, address}, and
{supplier-name, address} ![]()
Supplier-scheme.
(Easy proof omitted.) Hence, this is a lossless join decomposition.
The result of a sequence of lossless join decompositions is a
lossless join decomposition.
![]()
that relations on scheme R must satisfy.
Thus, G is not a superkey because ![]()
![]() R.
R.
![]()
that relations on scheme R must satisfy.
A is not a superkey and A ![]() BG is not trivial,
so the first decomposition is
BG is not trivial,
so the first decomposition is ![]() = ABG and
= ABG and ![]() = ACDE.
= ACDE.
Consider ![]() . A is clearly a superkey for
. A is clearly a superkey for ![]() , so we compute:
, so we compute:
![]() = B (trivial)
= B (trivial)
![]() = GE (trivial when restricted to
= GE (trivial when restricted to ![]() )
)
![]() = BGE (trivial when restricted to
= BGE (trivial when restricted to ![]() )
)
Thus, ![]() is in BCNF.
is in BCNF.
Consider ![]() . Compute:
. Compute:
![]() = CDE
= CDE
Thus, C is not a superkey for ![]() , and C
, and C ![]() D is
on
D is
on ![]() and not trivial. Decompose to produce
and not trivial. Decompose to produce ![]() = CD and
= CD and
![]() = ACE.
= ACE.
Consider ![]() . Clearly C is a superkey for
. Clearly C is a superkey for ![]() . Compute:
. Compute:
D+ = D (trivial)
Hence, ![]() is in BCNF.
is in BCNF.
Consider ![]() . Compute:
. Compute:
![]() = ABGE
= ABGE
Hence, A ![]() E holds, A is not a superkey for
E holds, A is not a superkey for ![]() ,
and A
,
and A ![]() E is not trivial. Decompose to produce
E is not trivial. Decompose to produce
![]() = AE and
= AE and ![]() = AC. From closures previously computed
and
= AC. From closures previously computed
and ![]() = E, these schemes are in BCNF. Hence, our decomposition
is:
= E, these schemes are in BCNF. Hence, our decomposition
is:
{ ![]() ,
, ![]() ,
, ![]() ,
, ![]() }
}
![]()
Use the union rule to produce:
![]()
If we replace A ![]() BG by A
BG by A ![]() B,
B,
![]() = AB, so we lose A
= AB, so we lose A ![]() G. Hence, G is
not extraneous.
G. Hence, G is
not extraneous.
If we replace C ![]() DE by C
DE by C ![]() D,
D,
![]() = CDE, so we can recover C
= CDE, so we can recover C ![]() DE. Hence, E
is extraneous.
DE. Hence, E
is extraneous.
![]()
If we replace CD ![]() E by C
E by C ![]() E,
we compute
E,
we compute ![]() = CDE in
= CDE in ![]() . Hence, C
. Hence, C ![]() E
is in
E
is in ![]() , and so D is extraneous.
, and so D is extraneous.
![]()
use the union rule to produce:
![]()
If we replace C ![]() DE by C
DE by C ![]() D,
D,
![]() = CD, so we can NOT recover C
= CD, so we can NOT recover C ![]() DE. Hence,
E is not extraneous.
DE. Hence,
E is not extraneous.
If we replace C ![]() DE by C
DE by C ![]() E,
E,
![]() = CE, so we can NOT recover C
= CE, so we can NOT recover C ![]() DE. Hence,
D is not extraneous.
DE. Hence,
D is not extraneous.
Thus:
![]()
Compute closures:
![]() = ABGE
= ABGE
![]() = CDE
= CDE
![]() = GE
= GE
Thus, no scheme contains a superkey for R (much less a candidate
key). However, ![]() = ACBGDE and clearly neither A nor C
is a superkey. Hence, AC is a candidate key and our
lossless join, dependency preserving 3NF decomposition is:
{ABG, CDE, GE, AC}
= ACBGDE and clearly neither A nor C
is a superkey. Hence, AC is a candidate key and our
lossless join, dependency preserving 3NF decomposition is:
{ABG, CDE, GE, AC}
![]()
that relations on scheme R must satisfy.
Consider ![]() . Since A is a superkey for
. Since A is a superkey for ![]() , and multivalued
dependencies with C on the left are all trivial on
, and multivalued
dependencies with C on the left are all trivial on ![]() (because C
(because C ![]() C is trivial and
C
C is trivial and
C ![]() A would be trivial on
A would be trivial on ![]() if it
held), this scheme is in 4NF.
if it
held), this scheme is in 4NF.
Consider ![]() . From the previous problem, we have
A
. From the previous problem, we have
A ![]() G and we know that A is not a
superkey for
G and we know that A is not a
superkey for ![]() . Since A
. Since A ![]() G is
not trivial for
G is
not trivial for ![]() , decompose into
, decompose into ![]() = AG and
= AG and
![]() = AB.
= AB.
By the reasoning used for ![]() , we can conclude that
, we can conclude that ![]() and
and
![]() are in 4NF. Hence, the decomposition is:
{
are in 4NF. Hence, the decomposition is:
{ ![]() ,
, ![]() ,
, ![]() }.
}.
Decomposition helps with inability to represent information because
this problem usually arises from attributes that are not closely
related being stored in the same relation. In this case, information
for one subset of the attributes will often be available when
the associated information for the remaining attributes is not
(leading to null values). Decomposition solves this problem by
splitting into schemes with only closely related attributes.