The implementation of a DBMS includes one or more files that contain the data conceptually stored in relations. One common implementation is a file for each relation, and a separate file for the data dictionary. A tuple is usually represented by a record (struct) in such a file.
For efficiency reasons, the files used to store relations are rarely simple sequential files. Instead, data structures called indices are used to make accessing particular records efficient. Common indexing techniques include hash tables and variants of B-Trees. Indexing techniques make looking up a particular record efficient, but often impose overhead on insertion and deletion time as well as space overhead.
For a particular relation, it may be useful keep multiple indices on different search keys. A search key is a subset of the attributes of the relation that is used to look up records. For example, for the customer relation we would certainly want an index on cust-num (the primary key), and likely also an index on name since looking up customers by name is a frequent operation. Note that a search key need not be a candidate key (or even a superkey).
One index is usually designated as the primary index, and records in the file are stored in sorted order on the primary index. The search key of a primary index is usually the primary key of the relation (assuming each relation is stored in a separate file). This allows easy sequential scanning of all records in the file in primary key order. All other indices on the file are secondary indices. Note that a secondary index structure can NOT assume that records are stored in sorted order on its search key. If the search key is not a candidate key, then each search key value can refer to multiple records (in random locations in the file). In this case, the value stored for each search key value is a set of file pointers (one to each of the relevant records). Such a set of file pointers is called a bucket. If one bucket is not sufficient to hold all of the pointers, a linked list of buckets is usually used.
Although the SQL-92 standard does not include syntax for creating and deleting indices, most implementations support fairly standard syntax for doing so. Most implementations also automatically create an index on the primary key of the relation.
If the user wishes to specify more indices, the syntax is:
create index index-name on
relation-name(attribute-list)
where the attribute list is the search key for the index.
For example, to create a secondary index on name for the customer relation:
create index cname-ind on
customer(name)
To specify that the search key is a candidate key, add unique
to the index definition:
create unique index index-name on
relation-name(attribute-list)
The system checks that the attributes listed are unique in the relation.
To remove an index:
drop index index-name
A B+ tree is a form of balanced search tree. B+ trees are probably the most popular index structure in relational database systems, even though they impose space overhead as well as overhead on insertion and deletion.
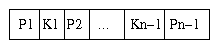
Each interior node of a B+ tree has the following form:
where each P is a pointer to a child node, and each K is a search key. Within a node, the search keys are kept in sorted order. Leaf nodes have the same structure, except that the pointers point to the appropriate records stored within the file itself. The last pointer in each leaf node points to the next leaf node. This allows easy sequential scan of the entire file in search key order.
The size of a node is usually determined by the block size used by the operating system. If each node (n pointers and n - 1 search keys) fits in a block, disk accesses can be reduced.
Each interior node except the root must have at least
![]() n/2
n/2![]() children. Each leaf node must contain
at least
children. Each leaf node must contain
at least ![]() (n - 1)/2
(n - 1)/2![]() search key values. These
conditions give a lower bound on space utilization, and help
in deciding when the tree must be reorganized for balancing.
search key values. These
conditions give a lower bound on space utilization, and help
in deciding when the tree must be reorganized for balancing.
The following B+ and file stores a sample customer relation with cust-num as the search key.

Here, n = 4 and the B+ is the primary index. Note that a B+ can be a secondary index, and it is still relatively easy to scan the file in the order specified by the search key for the secondary index. If the search key is a candidate key, no extra indirection is needed to use a B+ tree as a secondary index.
To find the record with search key value k:
The total number of nodes accessed is bounded above by
![]() for a file containing
m search key values. For n = 100, any search key in a file
containing one million search keys can be found by accessing at most 4 nodes.
for a file containing
m search key values. For n = 100, any search key in a file
containing one million search keys can be found by accessing at most 4 nodes.
To insert a record with search key value k:
Example: inserting the record (7, Prince Michael Jr., Neverland) causes our example tree to become:
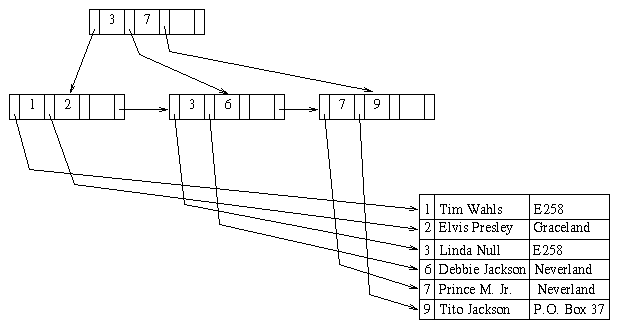
The rightmost child of the root was split. Instead of splitting a node when it becomes full, some variants of B+ trees try to redistribute search keys and pointers to sibling nodes. In our example, search key 3 could have been moved to the left sibling of the node that was split. This technique keeps space utilization higher, but does require adjusting search keys in the parent node.
To delete a record with search key value k:
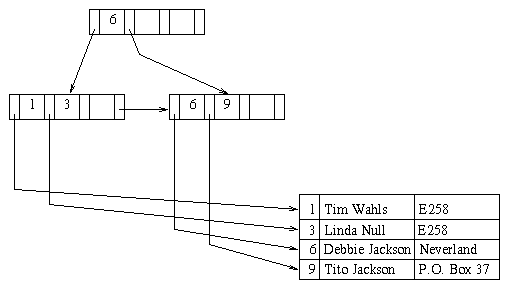
For example, if Elvis ever dies and is deleted from our original tree, redistribution occurs and the resulting tree is:
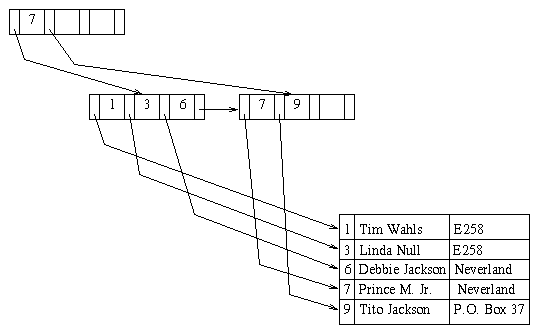
If Elvis is deleted from our second example tree, a leaf node is deleted and the resulting tree is:
Because all operations on B+ trees take time proportional to the logarithm of the number of search keys, and because B+ trees work well as both primary and secondary indices, they are a good index structure for implementing relational databases.