An integrity constraint is an arbitrary predicate pertaining to a database. We've already seen two forms of integrity constraints:
As testing integrity constraints can be time consuming, care must be taken when deciding what kinds of integrity constraints to enforce. Many older database systems explicitly limit the constraints that can be enforced, but SQL-92 does not.
In the relational model, each attribute of a relation has an associated domain. A domain constraint simply asserts that each attribute value of an inserted tuple is an element of that attribute's domain (type). This kind of constraint is easily tested each time a tuple is inserted.
Domain information also allows queries to be checked for sensibility. For example, the query:
select *
from customer, flyrod
where cust-num = manufacturer
compares a string and a number. Such an error should be found when the query is entered, not when it is executed.
SQL allows some further domain constraints to be expressed in the
create table command:
not null
check clause (SQL-92 only)
Examples using check:
A domain for manufacturers, assuming that the flyshop only stocks flyrods
by particular manufacturers. Note that the check clause can
be used in a create domain command, as well as in a
create table command.
create domain manufacturer-type char(30)
check(value in
("Orvis", "G. Loomis", "Winston",
"Sage"))
The keyword constraint can be used to give a name to such
a constraint. This allows the DBMS to report which constraint was violated
(by name) when an error occurs.
create domain manufacturer-type char(30)
constraint legal-manufacturers
check(value in
("Orvis", "G. Loomis", "Winston",
"Sage"))
In either case, the domain manufacturer-type would then be used as the domain of manufacturer in the flyrod relation.
Example: put bounds on flyrod lengths.
create domain flentype real
constraint flyrod-len
check(value > 0 and
value <= 20.0)
Example: make sure the flyrod-stock-num can't be null.
create domain fsntype int
constraint fsnkey
check(value not null and
value >= 0)
This kind of constraint is useful for primary key attributes.
In the relations purchased and flyrod, we expect that any flyrod-stock-num appearing in a tuple of purchased also appears in a tuple of flyrod. In relational algebra:
![]()
On the other hand, there may well be flyrod models that no one has purchased. That is, we do not require that:
![]()
Note that if:
![]()
then some tuples of flyrod or purchased (or both) will not participate
in flyrod ![]()
![]() purchased.
purchased.
A tuple that does not participate in a natural join is called a dangling tuple. Dangling tuples may indicate a consistency problem in the database.
Referential integrity constraints specify exactly when dangling tuples indicate a problem. To define referential integrity, we need the concept of a foreign key.
Let ![]() and
and ![]() , with
, with ![]() the primary key of
the primary key of ![]() and
and
![]() . The set of attributes
. The set of attributes ![]() is a foreign
key referencing
is a foreign
key referencing ![]() if for every tuple
if for every tuple ![]() , there is a tuple
, there is a tuple
![]() such that:
such that:
![]()
Equivalently: ![]()
A constraint of this form is called a referential integrity constraint
(or a subset dependency). Clearly, either ![]() or
or ![]() and
and ![]() are compatible.
are compatible.
Example: attribute flyrod-stock-num of purchased is a foreign key referencing the flyrod-stock-num attribute of flyrod, and:
![]()
is a referential integrity constraint.
Example: attribute cust-num of purchased is a foreign key referencing the cust-num attribute of customer, and:
![]()
is a referential integrity constraint.
Example: Any relation derived from an n-ary relationship set (E-R model) contains n foreign keys.
Example: attribute flyrod-stock-num of flyrod is NOT a foreign key referencing the flyrod-stock-num attribute of purchased, because flyrod-stock-num is not the primary key of purchased.
To ensure that referential integrity constraints are preserved, the constraints must be tested each time the database is modified.
Consider a referential integrity constraint of the form:
![]()
if tuple ![]() is inserted into
is inserted into ![]() , the database system must test that:
, the database system must test that:
![]()
i.e. that inserting the tuple won't violate the ![]() relationship.
relationship.
if tuple ![]() is deleted from
is deleted from ![]() , the system must test that no tuples of
, the system must test that no tuples of
![]() reference
reference ![]() :
:
![]()
If this condition is not satisfied, then either the deletion must be rejected,
or else the offending tuples must be deleted from ![]() . If there are more
referential integrity constraints involving
. If there are more
referential integrity constraints involving ![]() , this may cause more
deletions.
, this may cause more
deletions.
![]()
(same as insert).
![]()
(same as delete).
When a table is created in SQL, the following constraints can be specified
as part of the create table statement:
primary key - lists the attributes of the primary key
unique - lists the attributes of a candidate key
foreign key - lists the attributes of a foreign key and
the relation referenced
Example: creating the purchased relation:
create table purchased (
cust-num int not null,
flyrod-stock-num int not null,
date char(20) not null,
primary key (cust-num, flyrod-stock-num, date),
foreign key (cust-num) references customer,
foreign key (flyrod-stock-num) references
flyrod)
The implied referential integrity constraints are:
![]()
![]()
If the attribute names are different in the foreign relation, they can
be listed explicitly in the foreign key clause.
When a referential integrity constraint is violated, the default action
is for the system to reject the modification that caused the violation.
In SQL-92, a foreign key clause can specify that other actions
are taken to resolve the violation. These actions are modifications to one
or more relations.
Example: suppose that a deletion from the flyrod relation violates one of the
referential integrity constraints for purchased. Rather than having
the system report an error, we can specify in the create table
statement that the offending tuples in
purchased are deleted:
create table purchased (
...
foreign key (flyrod-stock-num) references
flyrod
on delete cascade)
Now, deleting a tuple in flyrod causes all tuples in purchased that mention the deleted flyrod to be deleted as well.
Other possible actions when a referential integrity constraint is violated:
create table purchased (
...
foreign key (flyrod-stock-num) references
flyrod
on delete cascade
on update cascade)
null or some other
default value
When a candidate key is specified using unique, the system
will check that any tuple inserted does not duplicate an existing tuple
on those attributes. Unless specifically stated using not null,
attributes listed in a unique clause may be null.
Functional dependencies are a class of integrity constraints that will be important in finding good database designs.
Let R be a relation scheme, and ![]() ,
,
![]() . The functional dependency
. The functional dependency ![]() holds on R if for all legal relations r(R), for all tuples
holds on R if for all legal relations r(R), for all tuples
![]() ,
, ![]() , if
, if ![]() , then
, then
![]() .
.
Example: for relations on Customer-scheme, each cust-num is associated
with at most one name: cust-num ![]() name
name
Example: if K is a superkey for relations on scheme R, then for any
![]() ,
, ![]() . In the customer relation:
. In the customer relation:
cust-num ![]() {name, address, cust-num}
{name, address, cust-num}
cust-num ![]() {name, address}
{name, address}
and so on.
Example: if Customer-scheme had attributes house-num, street, city, state and zip instead of address:
{house-num, street, city, state} ![]() zip
zip
because each house is in only one zip code.
Example:
| A | B | C |
|---|---|---|
| 1 | 5 | 3 |
| 2 | 6 | 4 |
| 3 | 7 | 4 |
| 1 | 4 | 3 |
In this relation, does A ![]() B hold?
B hold?
From top to bottom, label the tuples ![]() through
through ![]() . Then,
. Then,
![]() [A] =
[A] = ![]() [A], but
[A], but ![]() [B]
[B] ![]()
![]() [B]. In other words, the
answer is no, because the first and fourth tuples have the same value of A,
but different values of B.
[B]. In other words, the
answer is no, because the first and fourth tuples have the same value of A,
but different values of B.
Does A ![]() C hold?
C hold?
Yes, because the only tuples that agree on A are ![]() and
and ![]() , and
, and
![]() [C] =
[C] = ![]() .
.
Does AB ![]() C hold? (AB is shorthand for {A, B}.)
C hold? (AB is shorthand for {A, B}.)
Yes, trivially, because ![]() [AB]
[AB] ![]()
![]() [AB] for
[AB] for ![]() .
.
A trivial functional dependency ![]() is a
functional dependency in which
is a
functional dependency in which ![]() . Trivial f.d.s
always hold, because if two tuples agree on all attributes in
. Trivial f.d.s
always hold, because if two tuples agree on all attributes in ![]() ,
they can not disagree on a subset of
,
they can not disagree on a subset of ![]() .
.
Functional dependencies are associated with a relation scheme, rather than
with an instance. We can NOT assume that ![]() is
a f.d. on R just because it holds for some r(R). A f.d. must hold for
all r(R).
is
a f.d. on R just because it holds for some r(R). A f.d. must hold for
all r(R).
Functional dependencies can be specified in SQL-92 (using the
check clause), but this is not how they are usually used. Rather,
f.d.s are usually used only in designing the schemes of the relations in
the database.
A given set of f.d.s may imply that other f.d.s hold. For example,
if A ![]() B and B
B and B ![]() C, does A
C, does A ![]() C hold?
C hold?
proof of A ![]() B
B ![]() B
B ![]() C
C ![]() A
A ![]() C
C
Let ![]() and
and ![]() be any two tuples s.t.
be any two tuples s.t. ![]() [A] =
[A] = ![]() [A]. (If there
are no such tuples, then A
[A]. (If there
are no such tuples, then A ![]() C holds by default.)
C holds by default.)
Since ![]() [A] =
[A] = ![]() [A],
[A], ![]() [B] =
[B] = ![]() [B] by definition of
A
[B] by definition of
A ![]() B
B
Since ![]() [B] =
[B] = ![]() [B],
[B], ![]() [C] =
[C] = ![]() [C] by definition of
B
[C] by definition of
B ![]() C
C
Thus, if ![]() [A] =
[A] = ![]() [A], then
[A], then ![]() [C] =
[C] = ![]() [C]
[C]
A ![]() C by definition of functional dependency
C by definition of functional dependency
The closure of a set of f.d.s F (denoted F ![]() ) is the set of all
f.d.s logically implied by the f.d.s of F.
) is the set of all
f.d.s logically implied by the f.d.s of F.
Given a set of f.d.s F, F ![]() can be computed using Armstrong's axioms.
For sets of attributes
can be computed using Armstrong's axioms.
For sets of attributes ![]() ,
, ![]() ,
, ![]()
Theorem: Armstrong's axioms are sound and complete.
Soundness: if we conclude that ![]() from a set of
f.d.s F using Armstrong's axioms (correctly!), then F implies
from a set of
f.d.s F using Armstrong's axioms (correctly!), then F implies
![]()
Completeness: using only Armstrong's axioms, it is possible to compute all
of F ![]() from a set of f.d.s F. That is, we can find all f.d.s logically
implied by F using only Armstrong's axioms.
from a set of f.d.s F. That is, we can find all f.d.s logically
implied by F using only Armstrong's axioms.
Proof of soundness:
We've already argued that transitivity and reflexivity are sound.
Proof of Augmentation:
Assume ![]() and
and ![]() for arbitrary tuples
for arbitrary tuples ![]() and
and ![]() . To show:
. To show:
![]()
From ![]() ,
, ![]() and
and ![]() by reflexivity.
by reflexivity.
By ![]() and
and ![]() ,
,
![]() .
.
From ![]() and
and ![]() ,
,
![]() by definition of [ ].
by definition of [ ].
Thus, ![]() by definition of f.d.
by definition of f.d.
Proof of completeness: omitted.
To ease computing F ![]() , a number of additional rules are useful. The
soundness of these rules can be proved using Armstrong's axioms.
, a number of additional rules are useful. The
soundness of these rules can be proved using Armstrong's axioms.
Proof of soundness: union rule. Given ![]() and
and
![]() , show
, show ![]()
Example: Given R = {A, B, C, D, E, G} and F = {AB ![]() C,
BC
C,
BC ![]() D, D
D, D ![]() EG, BE
EG, BE ![]() C}, is
AB
C}, is
AB ![]() EG in F
EG in F ![]() ?
?
Simpler examples:
by D ![]() EG and decomposition, D
EG and decomposition, D ![]() E and
D
E and
D ![]() G
G
by D ![]() E, BE
E, BE ![]() C and psuedotransitivity,
BD
C and psuedotransitivity,
BD ![]() C
C
Given a set ![]() of attributes of R and a set of f.d.s F, we need a way
to find all of the attributes of R that are functionally determined by
of attributes of R and a set of f.d.s F, we need a way
to find all of the attributes of R that are functionally determined by
![]() . This set of attributes is called the closure of
. This set of attributes is called the closure of ![]() under F and is denoted
under F and is denoted ![]() . Finding
. Finding ![]() is useful because:
is useful because:
An algorithm for computing ![]() :
:
result :=
repeat
temp := result
for each f.d.in F do
ifresult then
result := result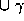
until temp = result
Example: Given R = {A, B, C, D, E, G} and F = {AB ![]() C,
BC
C,
BC ![]() D, D
D, D ![]() EG, BE
EG, BE ![]() C}, compute
AB
C}, compute
AB ![]()
| stage | result | using |
|---|---|---|
| 1 | AB | |
| 2 | ABC | AB -> C |
| 3 | ABCD | BC -> D |
| 4 | ABCDEG | D -> EG |
| 5 | ABCDEG |
Thus, AB is a superkey for R, because AB ![]() ABCDEG
ABCDEG
Correctness of the algorithm:
Need to show soundness (result ![]() ) and completeness
(
) and completeness
( ![]() result)
result)
Proof of soundness: by induction on iterations of the loop
basis: ![]() by reflexivity
by reflexivity
induction hypothesis: result at stage i, denoted result![]() , satisfies
result
, satisfies
result![]()
induction step: Consider a f.d. ![]() where
where
![]() result
result![]() . Then result
. Then result![]() by
reflexivity, and so result
by
reflexivity, and so result![]() by transitivity.
Hence, result
by transitivity.
Hence, result![]() result
result![]() by the union rule.
Since result
by the union rule.
Since result![]() by the I.H.,
by the I.H.,
![]() result
result![]() by definition. As
by definition. As
![]() result
result![]() = result
= result![]() ,
result
,
result![]() .
.
Proof of completeness ( ![]() result)
result)
(by contradiction) Let A ![]() R be such that A
R be such that A ![]() and A
and A ![]() result. Construct a relation r(R) with 2 tuples. The
tuples agree on all attributes of result, but disagree on all other attributes
of R.
result. Construct a relation r(R) with 2 tuples. The
tuples agree on all attributes of result, but disagree on all other attributes
of R.
lemma: r satisfies F
proof: (by contradiction) Assume r does not satisfy F. Then r must not satisfy
some f.d. ![]() in F. This can only happen if both
tuples in r agree on all attributes of
in F. This can only happen if both
tuples in r agree on all attributes of ![]() and disagree on some attribute
of
and disagree on some attribute
of ![]() . If both agree on all attributes of
. If both agree on all attributes of ![]() , then
, then
![]() result by the construction of r. But, if
result by the construction of r. But, if
![]() result and
result and ![]() ,
then
,
then ![]() result by the definition of the algorithm.
However, the tuples disagree on some attribute of
result by the definition of the algorithm.
However, the tuples disagree on some attribute of ![]() , so
, so
![]() result by the construction of r. This is a
contradiction, so the assumption that r does not satisfy F must be false,
i.e. r satisfies F.
result by the construction of r. This is a
contradiction, so the assumption that r does not satisfy F must be false,
i.e. r satisfies F.
end of lemma
We have A ![]() , so
, so ![]() A is logically implied
by F. Thus, any relation that satisfies F satisfies
A is logically implied
by F. Thus, any relation that satisfies F satisfies
![]() A.
A.
Thus, r satisfies ![]() A by the lemma.
A by the lemma.
Hence, the tuples of r agree on A by transitivity (since the tuples in r
must certainly agree on ![]() ).
).
Thus, A ![]() result by the construction of r. This contradicts the original
assumption, which must then be false. Hence,
result by the construction of r. This contradicts the original
assumption, which must then be false. Hence, ![]() result.
result.
Correctness of the algorithm:
by soundness and completeness,
result ![]() result
result
Hence, result = ![]()
If a relation must satisfy a set of f.d.s F, then we need to test that each
f.d. is satisfied each time the relation is updated or tuples are inserted.
For efficiency, we want the smallest set of f.d.s F ![]() possible such
that F
possible such
that F ![]() = F
= F ![]() .
.
A canonical cover F ![]() of a set of f.d.s F is a set of f.d.s
such that F
of a set of f.d.s F is a set of f.d.s
such that F ![]() = F
= F ![]() and for each f.d.
and for each f.d. ![]() in F
in F ![]()
Point 3 can be addressed using the union rule - combine
![]() and
and ![]() into
into
![]()
Points 1 and 2 must be checked directly. This is done by checking each f.d. in F for extraneous attributes, removing any such attributes found, combining f.d.s as in point 3 above where possible, and continuing this process until no more attributes can be removed.
Example: Given F = {CE ![]() A, C
A, C ![]() A,
C
A,
C ![]() B, AB
B, AB ![]() C, A
C, A ![]() B, B
B, B ![]() A},
find F
A},
find F ![]() .
.
Use the union rule to produce:
{CE ![]() A, C
A, C ![]() AB,
AB
AB,
AB ![]() C, A
C, A ![]() B, B
B, B ![]() A}
A}
To check if E is extraneous in CE ![]() A, we check that
C
A, we check that
C ![]() A in F
A in F ![]() , and that if we replace CE
, and that if we replace CE ![]() A
by C
A
by C ![]() A, CE
A, CE ![]() A is still in the closure.
A is still in the closure.
To check if C ![]() A is in F
A is in F ![]() , we compute C
, we compute C ![]() .
.
CAB - no need to go further as we have A
To check if CE ![]() A is still in the closure, we compute
CE
A is still in the closure, we compute
CE ![]() in the set of f.d.s:
{C
in the set of f.d.s:
{C ![]() A, C
A, C ![]() AB,
AB
AB,
AB ![]() C, A
C, A ![]() B, B
B, B ![]() A}
A}
CEA - no need to go further as we have A
Hence, E is extraneous. The current set of f.d.s is:
{C ![]() A, C
A, C ![]() AB,
AB
AB,
AB ![]() C, A
C, A ![]() B, B
B, B ![]() A}
A}
We can use the union rule again, producing:
{C ![]() AB,
AB
AB,
AB ![]() C, A
C, A ![]() B, B
B, B ![]() A}
A}
To check if the A is extraneous in C ![]() AB, we check if
C
AB, we check if
C ![]() B is in F
B is in F ![]() , and if C
, and if C ![]() AB is in F
AB is in F ![]() if we replace it by C
if we replace it by C ![]() B
B
Computing C ![]() : CAB - no need to go further as we have B
: CAB - no need to go further as we have B
To see if C ![]() AB is in the closure of:
{C
AB is in the closure of:
{C ![]() B,
AB
B,
AB ![]() C, A
C, A ![]() B, B
B, B ![]() A}
A}
CBA - done
Hence, the A is extraneous, and the current set of f.d.s is:
{C ![]() B,
AB
B,
AB ![]() C, A
C, A ![]() B, B
B, B ![]() A}
A}
To check if A is extraneous in AB ![]() C, we check if
B
C, we check if
B ![]() C is in F
C is in F ![]()
BAC - done
and if AB ![]() C is in the closure of:
{C
C is in the closure of:
{C ![]() B,
B
B,
B ![]() C, A
C, A ![]() B, B
B, B ![]() A}
A}
ABC - done
Hence, A is extraneous, and the current set of f.d.s is:
{C ![]() B,
B
B,
B ![]() C, A
C, A ![]() B, B
B, B ![]() A}
A}
Apply the union rule:
{C ![]() B, A
B, A ![]() B, B
B, B ![]() AC}
AC}
To check if A is extraneous in B ![]() AC:
AC:
Is B ![]() C in F
C in F ![]() ?
?
BAC - done
Is B ![]() AC in the closure of:
{C
AC in the closure of:
{C ![]() B, A
B, A ![]() B, B
B, B ![]() C}?
C}?
BC - done
No, so A is NOT extraneous:
To check if C is extraneous in B ![]() AC:
AC:
Is B ![]() A in F
A in F ![]() ?
?
BAC - yes!
Is B ![]() AC in the closure of:
{C
AC in the closure of:
{C ![]() B, A
B, A ![]() B, B
B, B ![]() A}?
A}?
BA - done
No, so C is NOT extraneous. Hence,
F ![]() = {C
= {C ![]() B, A
B, A ![]() B, B
B, B ![]() AC}
AC}
Note that the canonical cover is NOT unique. Other possible values for
F ![]() for this particular F are:
for this particular F are:
{A ![]() BC, B
BC, B ![]() A, C
A, C ![]() A}
A}
{C ![]() B, A
B, A ![]() C, B
C, B ![]() A}
A}
Any of these sets of f.d.s is much more efficient to test than the original F.